
The multimodal AI market hit $1.2 billion in 2023 and experts project a remarkable 30% annual growth through 2032. These systems can see, hear, and understand in ways never seen before, and they are reshaping the scene in our digital world. OpenAI’s move from text-only ChatGPT to image-processing GPT-4 marks a fundamental change in AI system’s capabilities.
Multimodal AI differs from traditional unimodal systems that process only one type of data. Modern multimodal models handle multiple information types at once – text, images, audio and more. This advanced approach to multimodal machine learning creates systems that better reflect human perception. GPT-4 Vision stands out among recent developments with its lifelike interactions through advanced multimodal deep learning techniques. These systems prove resilient to noise and missing data, and they maintain performance even when one modality fails. Multimodal learning boosts everything from healthcare diagnostics to autonomous vehicles by combining inputs from various sources to provide complete understanding and better decisions.
What Is Multimodal AI and Why It Matters in 2025
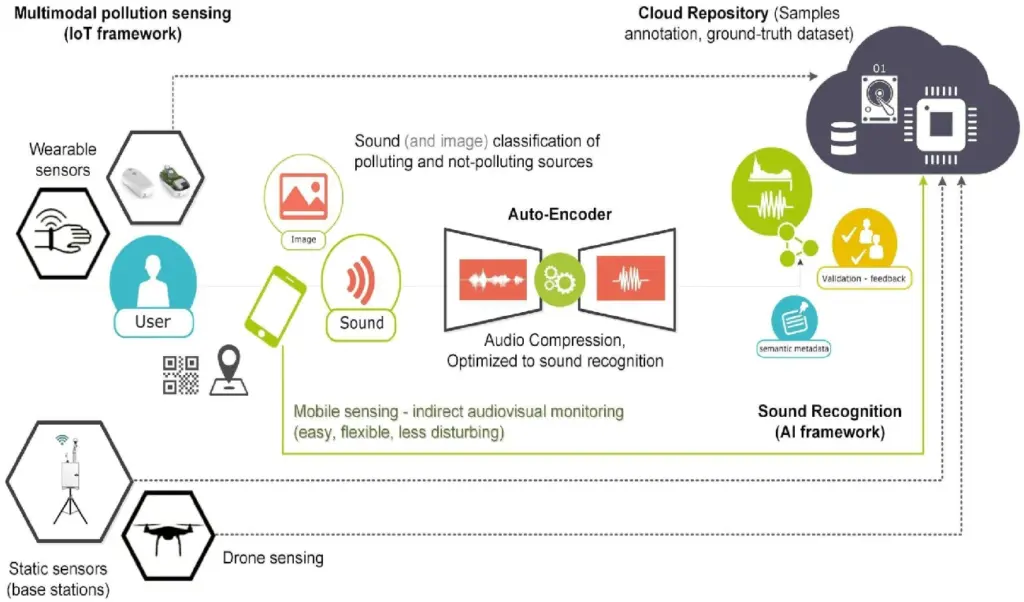
Image Source: Encord
AI experts aim to build systems that understand our world just like humans do. This goal serves as the life-blood of artificial intelligence. Multimodal AI brings a breakthrough approach to machine intelligence. It processes information through multiple dimensions instead of a single lens.
Definition of multimodal AI with examples
Multimodal AI systems know how to process and understand multiple types of data inputs at once—text, images, audio, video, and sensor data. These systems work like human perception. They blend different information streams to build detailed understanding, much like how we combine sight, sound, and touch to direct ourselves through our environment.
The architecture of multimodal AI has three basic components. The input module works as the system’s senses to gather and process different data types. The fusion module combines information from various sources to highlight key details and build a complete picture. The output module delivers the results to users.
Real-life applications show this capability at work. Amazon’s Alexa understands both verbal and visual commands while providing text-based responses and controlling smart home applications. Google’s Gemini can look at a photo of cookies and write out a recipe—or work backwards by creating images from written descriptions.
Multimodal vs unimodal AI: Key differences
The comparison between multimodal and unimodal approaches shows major differences in how AI systems work:
- Data handling: Unimodal systems work with one type of data (like text or images). Multimodal AI combines multiple data sources into one system that handles various inputs.
- Context comprehension: Unimodal models often miss supporting information they need for accurate predictions. Multimodal systems analyze problems more thoroughly and gather contextual details that lead to precise outputs.
- Complexity: Multimodal architectures need more sophisticated designs to blend and analyze multiple data sources at once. This demands greater technical expertise and resources.
- Performance: Both approaches excel at their specific tasks. Unimodal models struggle with context-heavy challenges. Multimodal systems handle these naturally by combining different information streams.
- Data requirements: Unimodal systems need huge amounts of single-type data for training. Multimodal models achieve strong performance with smaller datasets by using complementary information across modalities.
Why 2025 is a turning point for multimodal systems
The year 2025 marks a critical moment for multimodal AI development. Market projections show the global multimodal AI industry will reach USD 4.50 billion by 2028, growing at a compound annual rate of 35%. MarketsandMarkets predicts growth from USD 1.4 billion in 2023 to USD 15.7 billion by 2030, at a CAGR of 41.2%.
Technology breakthroughs make 2025 special. Transformer architectures now easily extend to handle multiple modalities. Access to massive labeled datasets (like YouTube-8M and OpenImages) has grown dramatically. Up-to-the-minute data analysis at the edge through specialized hardware makes deployment more practical than ever.
Models like GPT-4, Gemini, and LLaVA now join together in native multimodal training from scratch rather than as add-on extensions. This change toward unified models shows a fundamental development in how AI systems notice and interact with the world.
Gartner predicts that by 2026, about 60% of enterprise applications will use AI models that combine two or more modalities. This makes multimodal AI a standard requirement rather than an option. Businesses of all sizes now see multimodal approaches as essential parts of their technology stacks.
Core Architecture: How Multimodal AI Systems Are Built
Image Source: DataCamp
The architectural foundation of multimodal AI systems works like a sophisticated information processing pipeline that handles different types of data at once. These systems need three basic components that work together to achieve capabilities similar to human perception.
Input module: Unimodal neural networks for each data type
The multimodal architecture’s entry point has specialized unimodal neural networks that process different data types on their own. Each type of data needs its own dedicated processing pathway that’s optimized for that specific input:
- Text processing uses natural language processing techniques like tokenization, stemming, and part-of-speech tagging to extract meaning from written content.
- Image processing relies on convolutional neural networks (CNNs) to convert pixels into feature vectors that capture key visual properties.
- Audio processing changes sound into frequency-based features, often with specialized frameworks like Wav2Vec2.
These specialized networks act as the multimodal AI’s “sensory system” and prepare raw data for integration later. This preprocessing makes sure each type of data is normalized into a compatible format before fusion begins.
Fusion module: Early, mid, and late fusion strategies
The fusion module tackles the main challenge in multimodal architecture—deciding how and when to combine information from different sources. Three main strategies exist:
Early fusion combines different types of data right at the input level before much processing happens. This method treats the combined data as a single input stream for later processing. While it’s quick to compute, early fusion can have trouble with inconsistency because the extracted features become very sensitive to changes in data type.
Mid-level fusion (or intermediate fusion) processes each type of data separately into latent representations before combining them. This approach finds the sweet spot between flexibility and speed by keeping data-specific features while allowing meaningful integration. The integration often happens through attention mechanisms, graph convolutional networks, or transformer models.
Late fusion processes each type of data independently through separate models before combining their outputs or decisions. This method works like an ensemble where each data type makes its own prediction before final integration. Though it’s simpler, late fusion might miss important low-level interactions between different types of data.
Output module: Generating predictions and actions
The output module creates final results based on the combined information. This component changes the unified representation into specific outputs such as:
- Classification decisions or predictions
- Generated content (text, images, audio)
- Action recommendations for autonomous systems
Applications range from medical diagnostics to robotic automation in self-driving cars, which determines the output format. For decision-making systems, the module classifies the fusion module’s output and provides context around predictions.
Transformer-based integration in multimodal learning
Transformer architectures have become crucial to multimodal learning because they work well with all types of data. These transformers, which were first created for language tasks, have fewer data-specific requirements than traditional architectures.
The transformer’s core component—the self-attention mechanism—treats input sequences as fully-connected graphs where each piece of data acts as a node. This lets transformers handle different data types through one universal processing framework.
Multi-head attention proves especially valuable in multimodal contexts. Models can pay attention to information from multiple representation subspaces at once. Cross-attention mechanisms let each type of data be processed based on others without adding computational complexity.
Modern systems like IRENE show how transformers can build unified multimodal diagnostic architectures that learn comprehensive representations instead of processing data types separately. These systems use bidirectional multimodal attention blocks to encode connections between different types of data, similar to how human experts combine various information sources.
Key Challenges in Multimodal Deep Learning
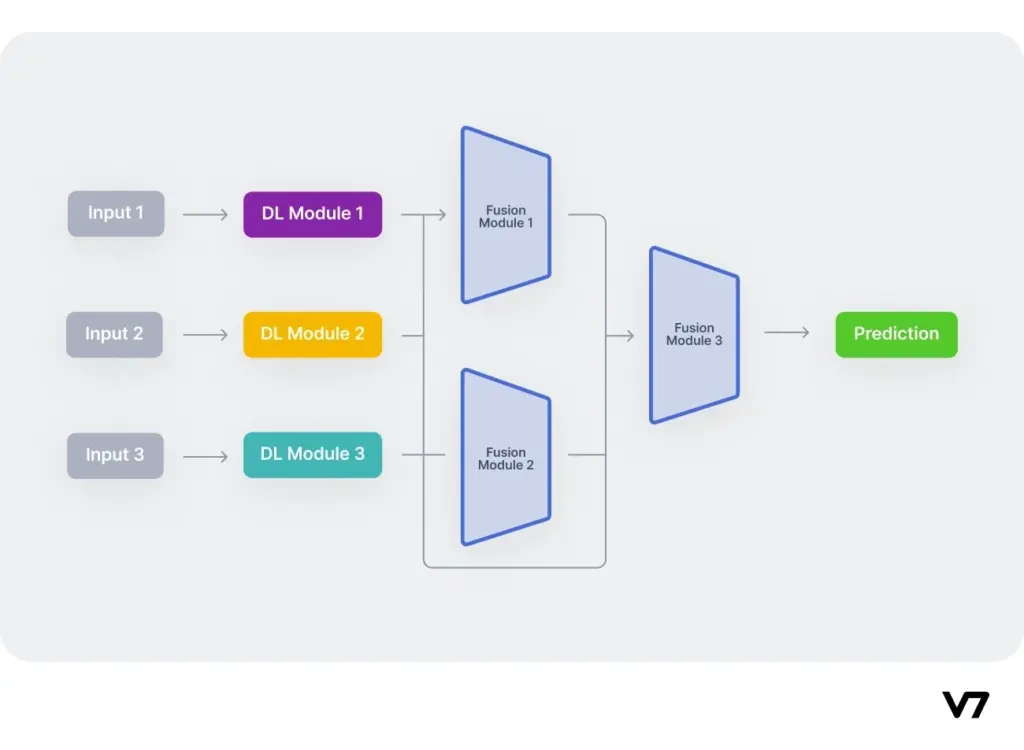
Image Source: V7 Labs
Multimodal technology has made remarkable progress, yet researchers still face basic challenges that hold these systems back. The need to overcome these obstacles grows more significant as this field continues to evolve toward reliable and effective AI solutions.
Data alignment across modalities
The biggest technical challenge in multimodal learning remains alignment. This process creates direct relationships between elements from different data types. Information must be synchronized in time, space, and context before meaningful integration can happen.
Alignment approaches fall into two main categories:
- Explicit alignment directly measures inter-modal relationships using similarity matrices
- Implicit alignment serves as an intermediate step for downstream tasks like translation or prediction
Fusion processes often lead to misinterpretations or critical information loss without proper alignment. To cite an instance, matching action steps in videos with their textual descriptions becomes challenging because input-output distributions vary and information between modalities might conflict.
Representation learning for heterogeneous inputs
Multimodal representation encodes data from multiple sources into vector or tensor forms. Each modality’s fundamentally different nature complicates this process. Images exist as pixel matrices, text as discrete sparse vectors, and audio as continuous waveforms. This makes unified representation particularly challenging.
Two primary approaches have emerged to address this challenge:
- Joint representation encodes individual modalities and places them into a mutual high-dimensional space
- Coordinated representation encodes each modality separately but coordinates them through imposed restrictions
The perfect representation should capture complementary information and ignore redundancies. This balance becomes harder to achieve with noisy or missing data.
Cross-modal reasoning and generation
Cross-modal reasoning integrates knowledge from multiple modalities through inferential steps. This creates unique obstacles for multimodal systems. These challenges grow when generating new content that must maintain cross-modal coherence and structure.
Text-to-image conversion tasks remain difficult because translations have no single “correct” answer and are inherently open-ended. Models like DALL-E show promising approaches by building generative systems that translate effectively between text and visual modalities.
Bias and fairness in multimodal models
Research reveals a concerning trend – combining multiple modalities can increase bias and reduce fairness compared to using the least biased unimodal component. Each modality might encode information about unrelated traits like gender or age. This creates more opportunities for unfair predictions.
Bias becomes harder to track in multimodal systems as it compounds across modalities. Facial recognition might encode cultural bias while language models reflect demographic stereotypes. These biases amplify rather than cancel each other out when combined. This raises serious ethical concerns for deployment in critical areas like healthcare, hiring, and security.
Real-World Applications Across Industries
Image Source: SmartDev
Multimodal AI systems give real benefits by processing multiple data streams at once. These real-life applications show how multimodal learning revolutionizes operations in a variety of sectors.
Healthcare: Combining imaging and patient records
Healthcare data naturally comes in many forms. It includes electronic health records (EHR), medical imaging, and patient demographics. Studies show that mixing imaging with clinical metadata makes diagnosis more accurate. Patient records help radiologists make better diagnoses. Without clinical data, their diagnostic performance drops by a lot. Modern multimodal models, especially transformer-based architectures, now process both imaging and non-imaging patient data better than single-modality approaches. A multimodal model that looked at chest X-rays along with clinical data showed better diagnostic results for all tested conditions.
Retail: Visual search and individual-specific recommendations
Visual search technology changes how people shop by letting them find products using images instead of keywords. Research suggests that shoppers who use visual search add more items to their cart and buy more than those using keyword search. One retailer’s conversion rates jumped 4X after adding visual search tools. Shoppers using visual search looked at 37% more products and spent 36% more time on websites. They also came back 68% more often.
Autonomous vehicles: Sensor fusion for live decisions
Autonomous vehicles need multimodal sensor fusion to direct safely. These systems create detailed 3D models of their surroundings by combining data from cameras, radar, and LiDAR sensors. Raw-data fusion creates dense and precise environmental models that spot small obstacles and unclassified objects better. This approach helps overcome each sensor’s limits. Cameras give visual information, LiDAR measures exact distances, and radar works well in bad weather.
Customer service: Emotion-aware virtual assistants
Virtual assistants now focus on emotional intelligence. AI assistants understand customer feelings and respond with empathy by mixing features like speech-to-text and text-to-speech. They analyze tone, pitch, and vocal features to grasp emotional context and adjust their responses. Research proves that emotionally smart virtual assistants make users happier and build stronger human-AI connections.
Security: Audio-visual threat detection
Audio surveillance works with video surveillance to create better security systems. Audio monitoring catches suspicious sounds even outside camera view and provides vital context. Security systems with vocal aggression detection spot stress in voices and warn the core team through visual or sound alerts. Two-way audio lets security staff talk to visitors, give warnings, and calm dangerous situations without physical contact.
Future Trends in Multimodal AI Development
AI development shows exciting new trends that reshape how multimodal systems process and understand our world. These new directions show AI’s growing sophistication that will change the way humans and computers interact.
Unified models like GPT-4o and Gemini
The AI industry moves faster toward unified multimodal architectures. These systems process multiple data types natively instead of using add-on extensions. OpenAI’s GPT-4o (“o” for “omni”) and Google’s Gemini family lead this new generation of systems. GPT-4o matches GPT-4 Turbo’s performance on text and code. It runs twice as fast at half the cost. Gemini has grown by a lot since the 2025 launch of Gemini 2.0. The new version focuses on the “agentic era” where AI systems understand environments, predict actions, and work for users. Both systems show how multimodal capabilities are now essential features of advanced AI.
Real-time multimodal processing in AR/VR
Immersive environments serve as testing grounds for advanced multimodal interactions. By 2027, about 40% of companies will use multimodal AI technologies. This number stood at just 1% in 2023. AR and VR settings make user experiences more natural through combined gestural, voice, and gaze interactions. This blend recognizes hand gestures, voice commands, and head movements instantly. These inputs become meaningful actions in virtual spaces. Research shows that users who can customize their input combinations complete tasks more efficiently and enjoy better experiences.
Cross-modal generation: Text-to-video and audio-to-image
Cross-modal generation has made amazing progress. Users can now turn written prompts into professional video clips. The technology also converts audio descriptions into images. These tools create five-second video clips at 1080p resolution. Content creators and educators find these tools valuable. Researchers publish more papers in this field as they learn about new ways to generate cross-modal content.
Open-source collaboration and model fine-tuning
Open-source multimodal models compete well with proprietary systems. Projects like LLaVA, CogVLM, and Molmo AI show the power of affordable solutions. Parameter-efficient fine-tuning (PEFT) methods help customize large multimodal models without changing all parameters. Adapter-based fine-tuning works best with datasets of all types. Organizations can now build custom solutions for specific needs without training models from scratch. This makes multimodal technology available to more users.
Conclusion
Multimodal AI has reached a turning point in 2025. What started as experimental technology now sees mainstream adoption across industries. This piece explored these systems’ ability to process multiple data types at once. They mirror human perception through sophisticated architectures that see, hear, and understand our world.
The market numbers tell a compelling story. A dramatic growth from $1.2 billion in 2023 to projected figures above $15 billion by 2030 shows the tremendous value these systems bring. Multimodal AI outperforms its unimodal counterparts with unmatched context comprehension. It combines various information streams into unified intelligence frameworks.
The core architectural components – input modules, fusion strategies, and output generation – create systems that bridge different modalities. Transformer-based integration has become crucial. It handles different data types through universal processing frameworks.
Major challenges still exist. Teams must tackle data alignment across modalities, representation learning for diverse inputs, and cross-modal reasoning. Ethical concerns about compounded bias need careful attention as these technologies move forward.
Ground applications highlight the technology’s importance. Healthcare professionals boost their diagnostic accuracy by combining medical imaging with patient records. Retailers transform shopping through visual search. Self-driving cars guide themselves safely by joining data from multiple sensors. Virtual assistants improve customer service through emotion awareness. Security systems detect threats better by integrating audio-visual inputs.
The future looks promising. Unified models like GPT-4 and Gemini 2.0 will grow beyond their current capabilities. Immediate multimodal processing will boost AR/VR experiences. Cross-modal generation opens new creative possibilities. Open-source efforts make these powerful technologies available to more people.
The multimodal approach matches AI development with human cognition. Our brains naturally blend sight, sound, and context to understand surroundings. AI systems following similar principles offer more intuitive interaction. This joining of human and artificial intelligence creates more natural, useful, and available technology for everyone.